
Photo by LucasVphotos on Unsplash
MJ12bot 蜘蛛是一隻來自英國的搜索引擎網站,照理說搜索引擎的蜘蛛是不該擋掉的,如果你用到一個小記憶體或 CPU 很爛的 VPS,一下子就會被 MJ12bot 蜘蛛搞掛掉;他不像一般正常的 Googlebot,文件爬完後就離開,MJ12bot 一來就是好幾個小時,造成服務器極大的壓力。
內容目錄:
- 阻擋 MJ12bot
- 代碼的作用
- Webinoly 安裝 VPS 教學系列文章
如下圖可見,MJ12bot 蜘蛛可以造成 CPU 負載極高,服務器資源被耗光。
CPU Graphs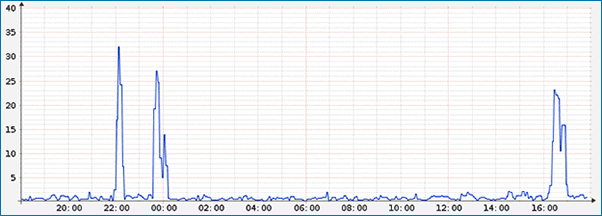
Traffic Graphs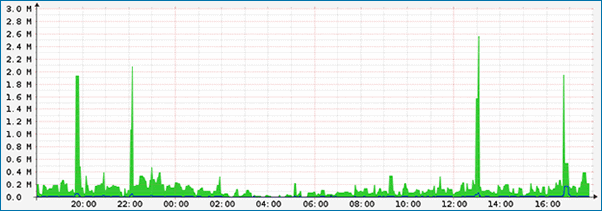
阻擋 MJ12bot
使用 Nginx conf 文件,將下方的設置存為 agent_bot.conf 文件,或直接添加在 nginx.conf 文件的 server 段配置裡:
if ($http_user_agent ~* (ApacheBench|pingback|YisouSpider|MJ12bot|AhrefsBot|360JK|Jorgee) ) {return 101;}
if ($http_user_agent = "" ) {return 101;}
if ( $request = "POST /reg.html HTTP/1.1" ) {return 400;}
if ( $request = "POST / HTTP/1.1" ) {return 400;}
if ( $request = "POST / HTTP/1.0" ) {return 400;}
if ( $request = "POST // HTTP/1.0" ) {return 400;}存為 agent_bot.conf 文件,用 SFTP 上傳到 /var/ www/yungke.me/conf/nginx 資料夾下。
重啟 Nginx 程序
nginx -t && service nginx restart代碼的作用
這段代碼的作用是 Nginx 檢測到相對應的條件,就把這個請求直接轉出。避免請求數據庫和 PHP 程序,減輕服務器的處理負擔。由於 Nginx 處理靜態內容的效率很高,所以可以最大限度的避免服務器資源被耗光。
自己模擬蜘蛛爬取:
curl -I -A 'mj12bot' https://yungke.me回應:
HTTP/1.1 101
Server: nginx
Date: Sun, 02 Jul 2017 11:17:47 GMT
Content-Type: application/octet-stream
Content-Length: 0
Connection: upgrade回應為 HTTP/1.1 101,已經成功將 mj12bot 導向到 101。
curl -I -A 'Googlebot' https://yungke.me回應:
HTTP/1.1 200 OK
Server: nginx
Date: Sun, 02 Jul 2017 11:21:11 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
Vary: Accept-Encoding
Link: ; rel="https://api.w.org/"
X-SRCache-Fetch-Status: MISS
X-SRCache-Store-Status: BYPASS
Strict-Transport-Security: max-age=31536000正常的好蜘蛛爬取,回應 HTTP/1.1 200 OK,表示可以正常爬取你的網站。
其他的問題:
- 如果你發現用了以上代碼後,有些功能失靈,那麼就檢查下過濾的關鍵詞。如果你想過濾更多的內容也可以加入更多的關鍵詞。
- 還有就是加入 pingback 過濾請求,可以阻擋比較低能 CC 請求,但是如果你的服務器比較低階。比如你的服務器的 CPU 不夠力 ,那麼還是極其容易 Nginx 佔用到 CPU 100% 而導致網站無法訪問,所以最終是拼服務器的性能。
- 不管 Nginx 回應是 403 還是 101,都需要 Nginx 給出處理和回應,雖然避開了 MySQL 及 PHP 其實結果還是要用到 CPU,CPU 性能不能太弱。
參考資料:
https://xuri.me/2015/03/18/anti-bad-bots-and-crawlers-by-user-agent.html

發佈留言